deepswe.datacurve.ai
DeepSWE
DeepSWE measures frontier coding agents on original, long-horizon software engineering tasks.
Visit deepswe.datacurve.ai ->
Only curated links
A handpicked collection of benchmark sites for comparing AI models, coding agents and real-world performance.
Benchmark
DeepSWE measures frontier coding agents on original, long-horizon software engineering tasks.
Compare AI and LLM benchmarks across reasoning, coding, math, vision and tool use. Every benchmark has a live leaderboard ranking 300+ models by independently verified score.
LLM rankings and AI leaderboard based on benchmarks and real usage data from millions of users. See which AI models developers actually use.
Compare AI model performance on Coding Index. Evaluates models' ability to solve programming problems, including those requiring scientific and research domain knowledge.
Private, domain-specific benchmarks in legal, tax, and finance.
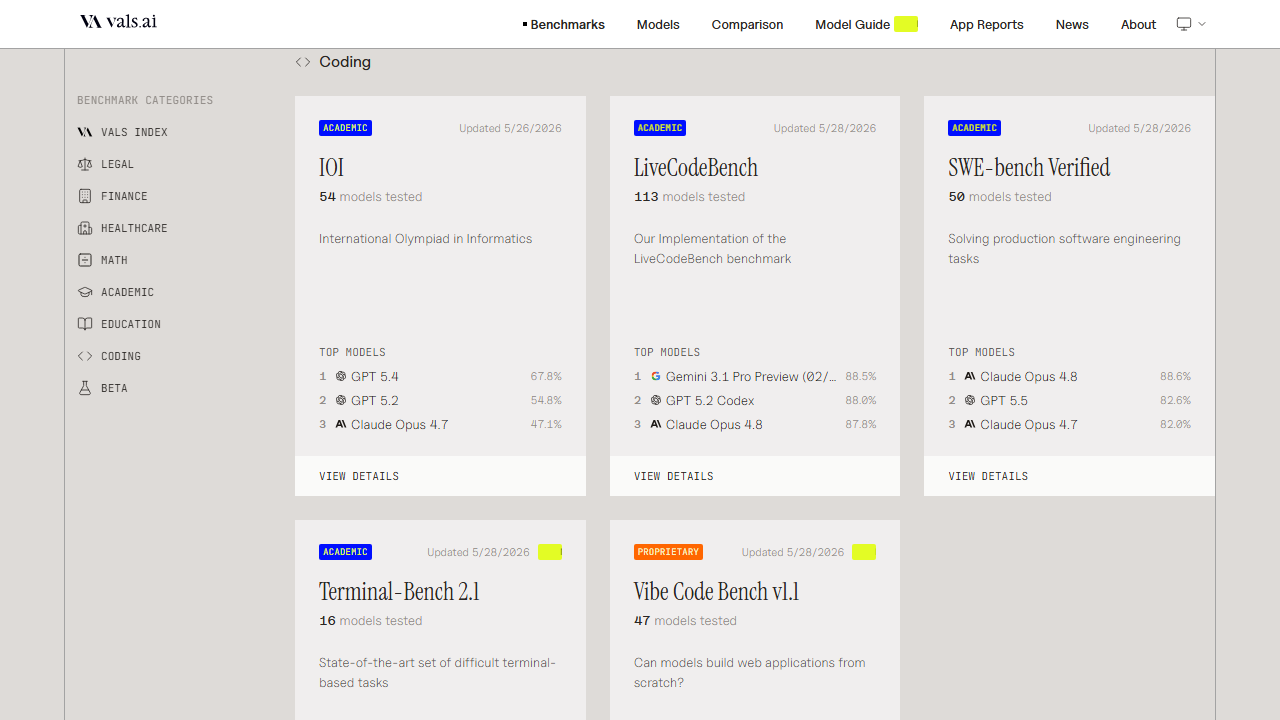
Explore leaderboards with expert-driven LLM benchmarks and updated AI model rankings across coding, reasoning and more.
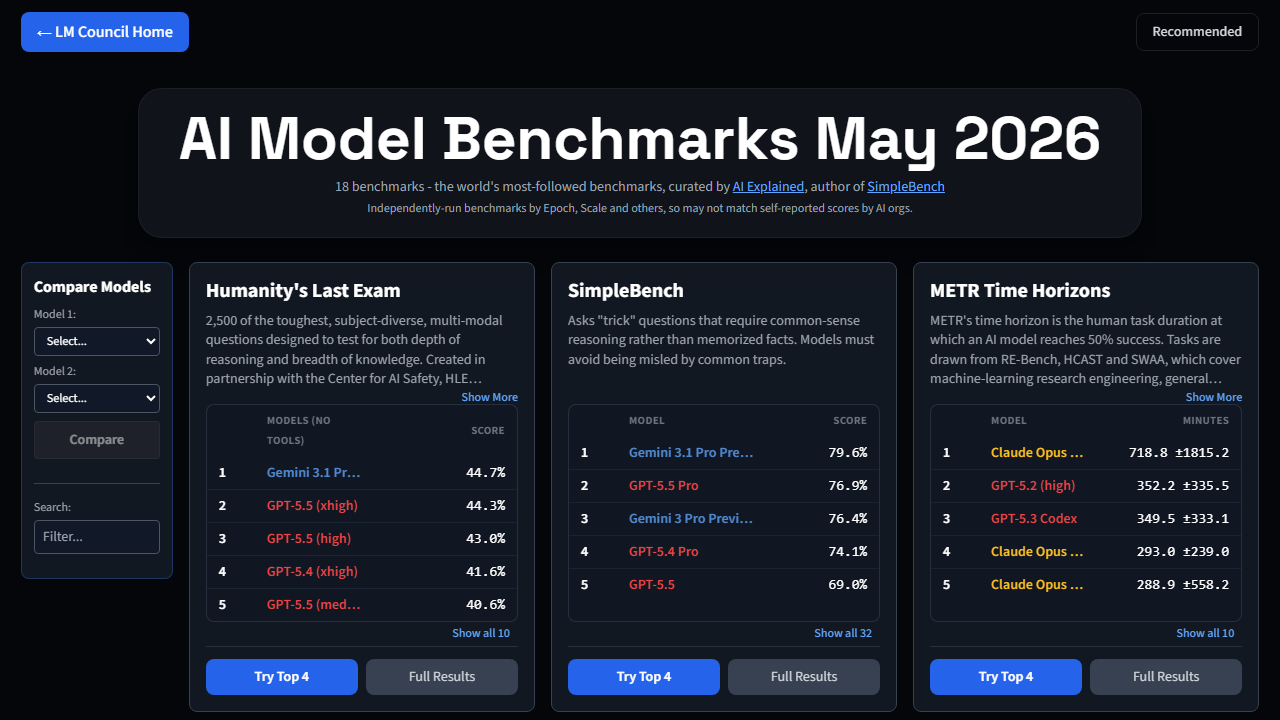
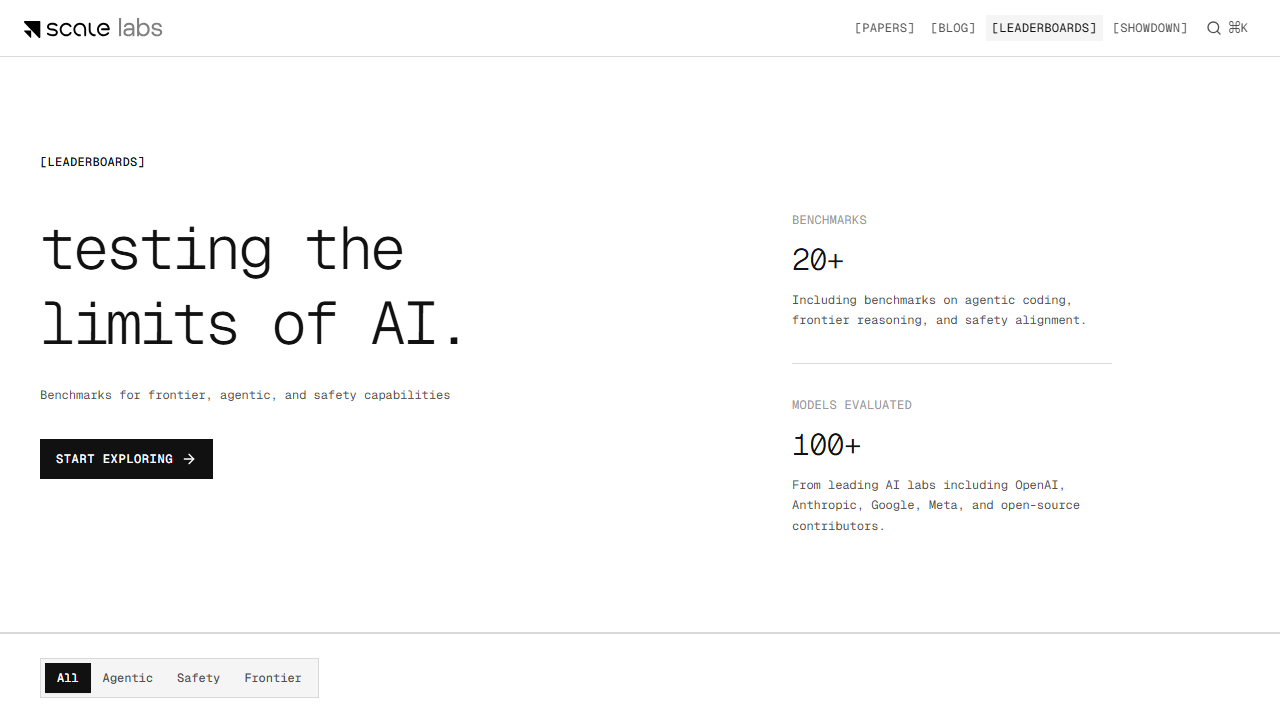
Comprehensive AI model benchmarks from Epoch AI and Scale AI. Compare GPT-5.5, Claude Opus, Gemini 3, Grok 4, and 30+ frontier models across curated benchmarks including Humanity's Last Exam, FrontierMath, GPQA, SWE-bench, and more. Interactive comparison tool with current results.
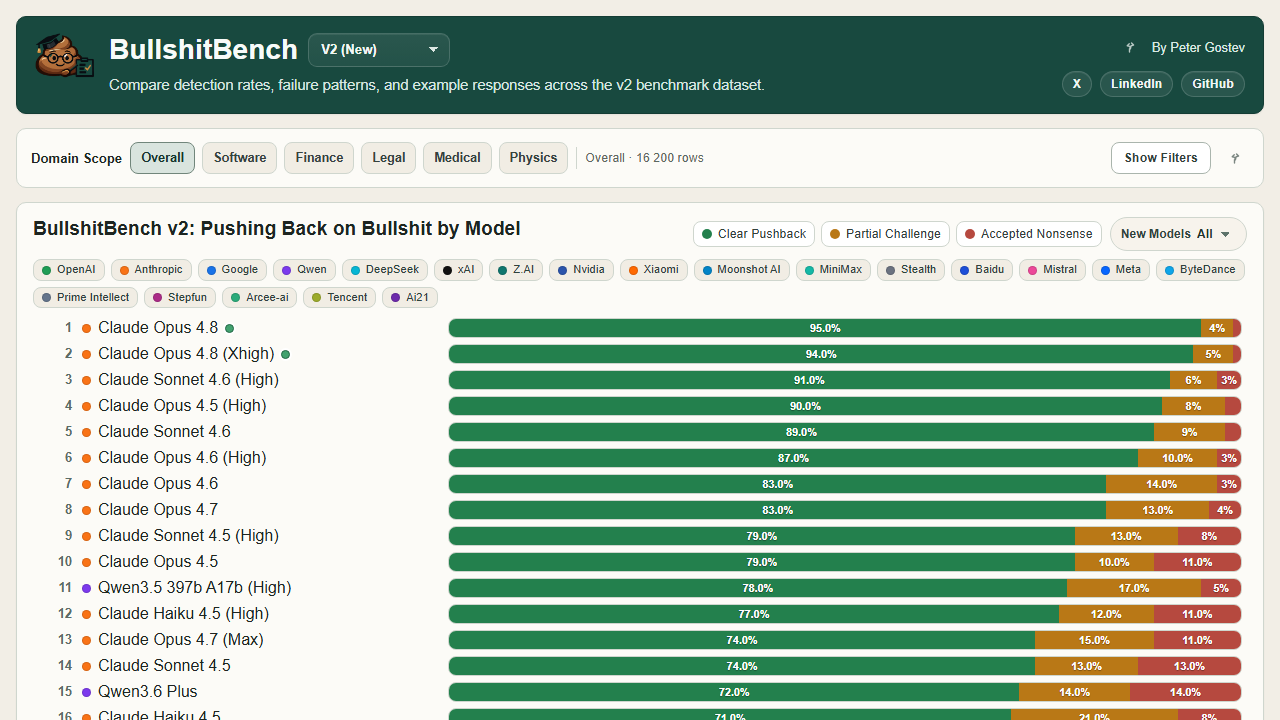
Explore benchmark and evaluation details from petergpt.github.io in a focused external resource.
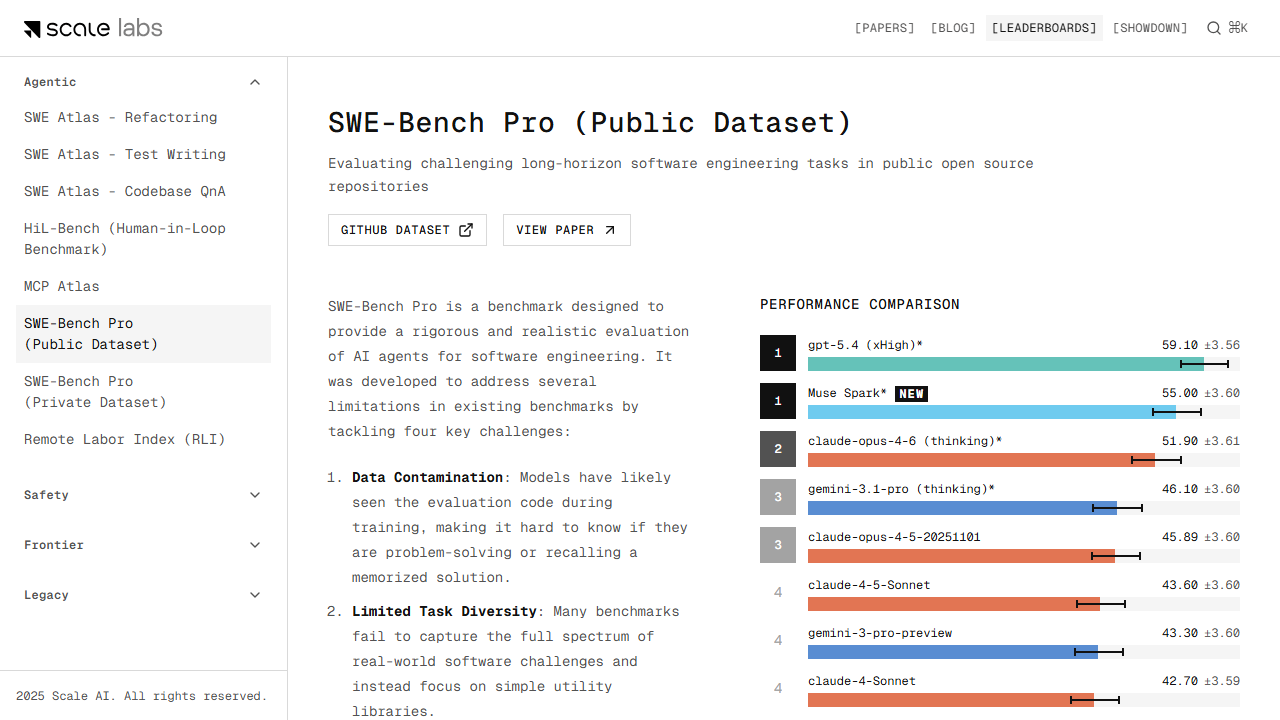
Compare the resolve rates of GPT-5.4, Muse Spark, Claude Opus 4.6, and Gemini 3.1 Pro on SWE-Bench Pro. A rigorous AI software engineering benchmark for...
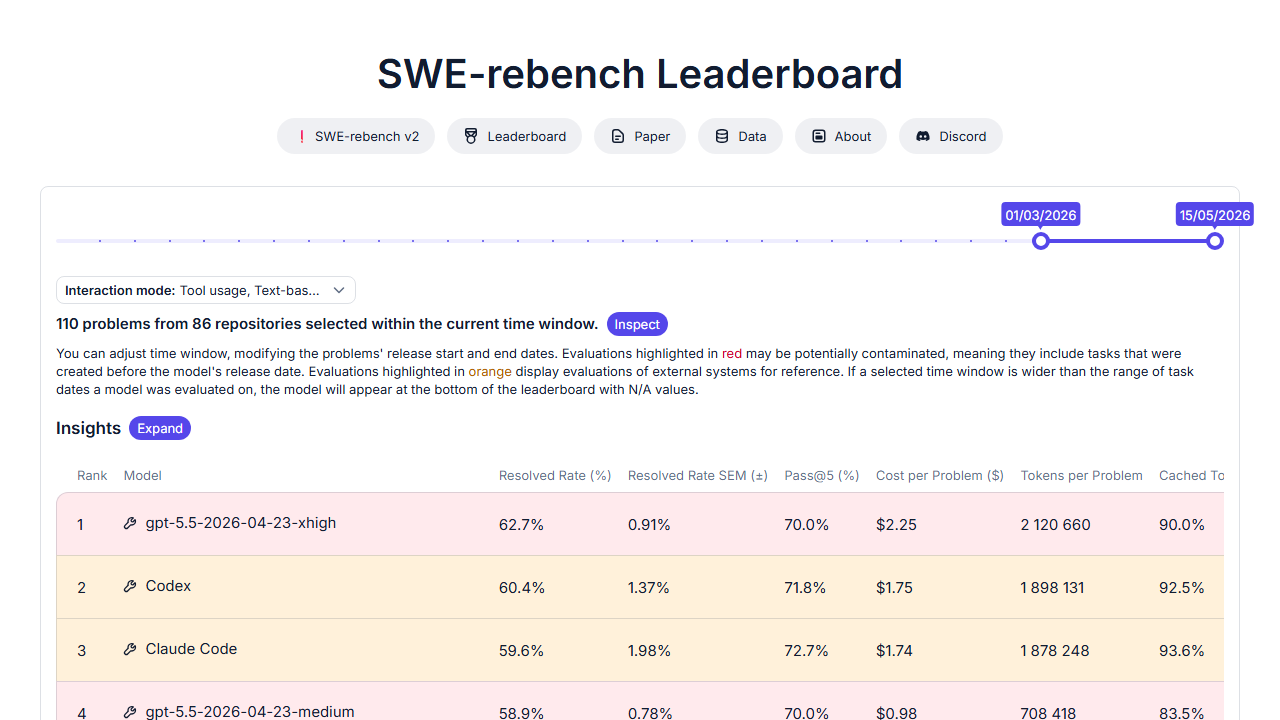
SWE-rebench: A Continuously Evolving and Decontaminated Benchmark for Software Engineering LLMs.
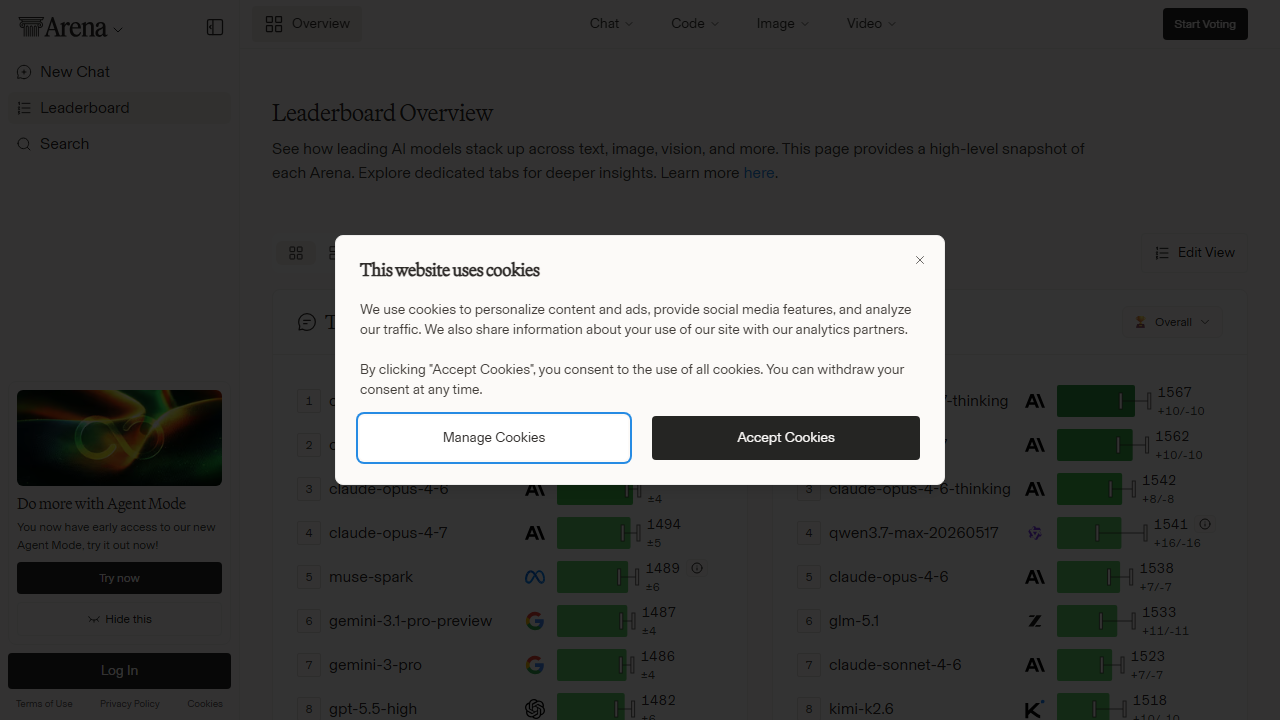
See how leading AI models stack up across text, image, vision, and more. This page provides a high-level snapshot of each Arena. Explore dedicated tabs for deeper insights.
Explore benchmark and evaluation details from bridgebench.ai in a focused external resource.
Benchmark
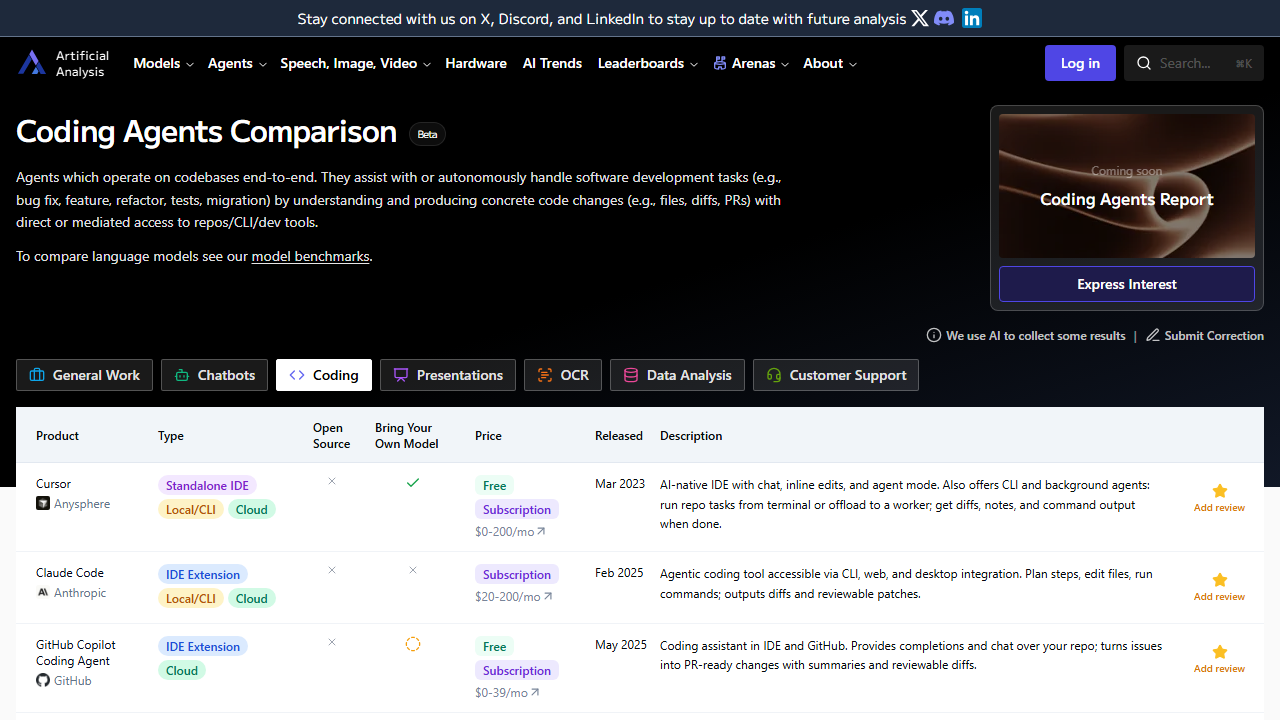
Comprehensive comparison of AI coding agents including Cursor, GitHub Copilot, Cline, Continue, and more. Compare IDE extensions, proprietary IDEs, CLI tools, and cloud platforms to find the best coding assistant for your development workflow.
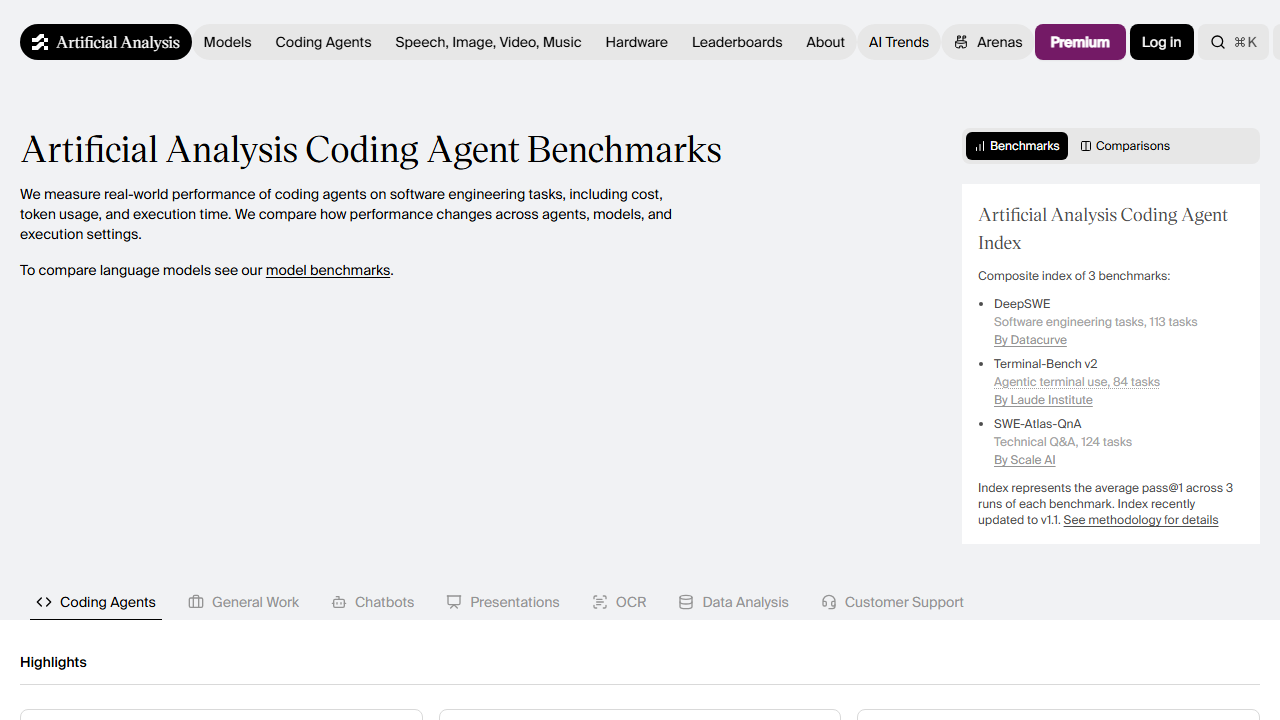
We measure real-world performance of coding agents on software engineering tasks, including cost, token usage, and execution time. We compare how performance changes across agents, models, and execution settings.
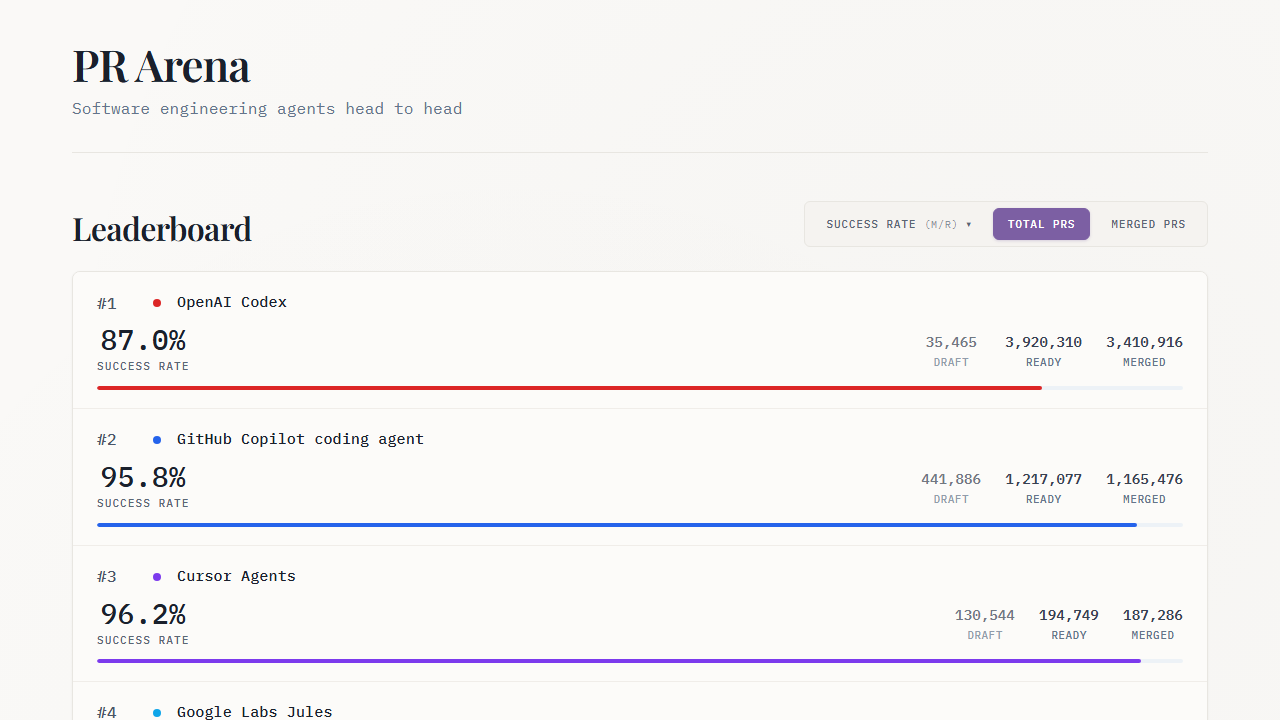
Explore benchmark and evaluation details from prarena.ai in a focused external resource.
Looking for a Cursor, Copilot, or Windsurf alternative? See how Kilo Code compares to the top AI coding assistants — open source, 500+ models, zero markup, BYOK everywhere.
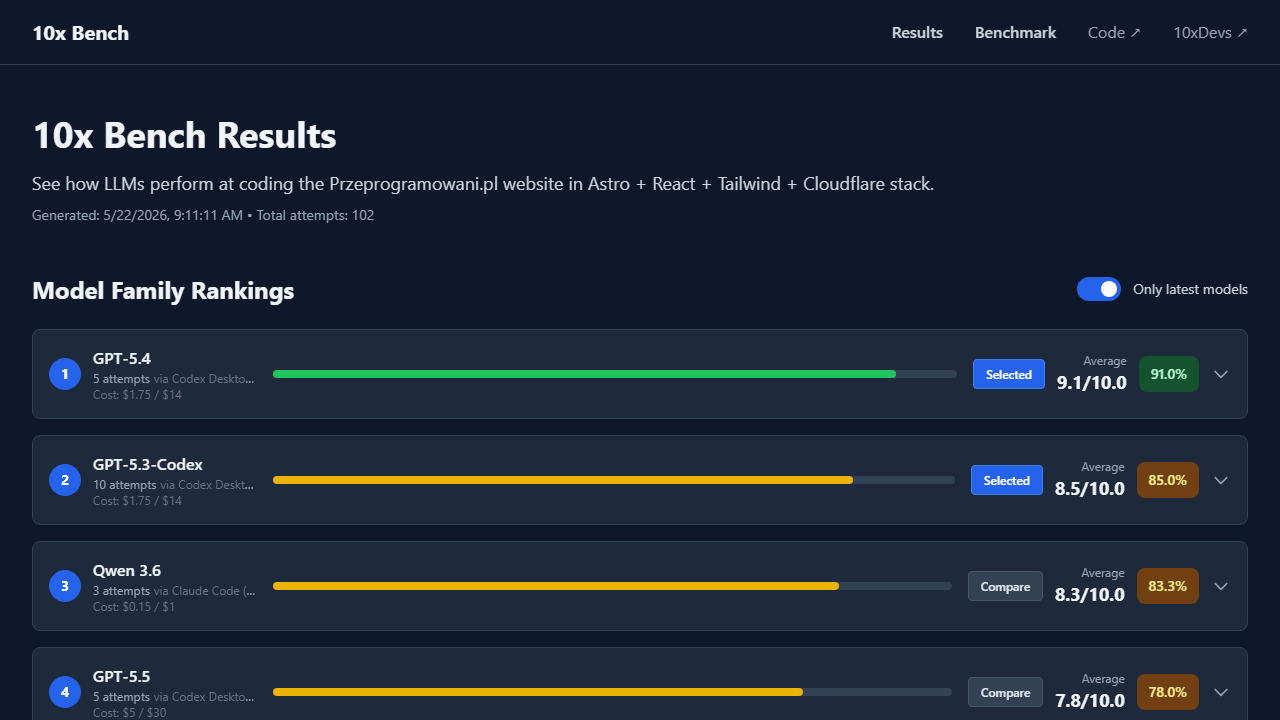
See how leading LLMs perform when each gets a single shot at building a real production website in Astro, React, Tailwind and Cloudflare. Compare scores, screenshots and generated code side by side.